One of our client’s PostgreSQL 16.8 production databases started logging what looked like a memory error:
ERROR: invalid memory alloc request sizeThe error immediately pointed toward two likely suspects:
- Memory exhaustion
- Memory corruption
As it turned out, neither was the culprit. Instead, it had encountered a known PostgreSQL bug that trapped the checkpointer in an infinite retry loop. The only way to recover was a forced restart, followed by an extended period of WAL replay during crash recovery.
This article explains what happened, why manual checkpoints couldn’t fix it, and how a PostgreSQL minor version upgrade permanently resolved the issue.
Understanding the purpose of a checkpoint
When a transaction modifies data, PostgreSQL does not immediately write the changed page to disk. Instead, it follows a two-step process:
- Write the change to the Write-Ahead Log (WAL) – a sequential, append-only record of every modification.
- Keep the modified page in shared memory as a dirty buffer until it is written later.
This design is intentional. WAL writes are sequential and therefore inexpensive, whereas writing data pages directly to their final location requires random disk I/O, which is much more costly. Decoupling these two operations is a fundamental part of PostgreSQL’s I/O architecture.
Eventually, however, the dirty buffers in memory must be synchronized with the actual data files on disk. That is the job of a checkpoint.
During a checkpoint, the checkpointer:
- Flushes every dirty buffer from shared memory to its corresponding data file.
- Calls fsync() on those files to ensure the data has reached durable storage rather than remaining in the operating system’s cache.
- Records the checkpoint location in the WAL once all writes have been safely persisted.
This checkpoint record is critical for crash recovery. If PostgreSQL crashes, recovery only needs to replay WAL generated after the most recent completed checkpoint, because everything before that point has already been written safely to disk. Without checkpoints, PostgreSQL would have to replay the entire WAL history from the beginning, making recovery increasingly slow as WAL accumulates.
To keep track of which files still require an fsync() before a checkpoint can finish, the checkpointer maintains an internal structure called the fsync request queue. Every data file modified during checkpoint processing is added to this queue. As each file is successfully fsynced, its entry is removed.
Under normal conditions, the queue drains steadily until the checkpoint completes. The problem begins when it doesn’t.
The Bug
The fsync request queue is implemented as a single contiguous memory structure inside PostgreSQL. Every file that still needs an fsync() during checkpoint processing occupies an entry in this structure. As more files are added, PostgreSQL dynamically resizes the queue to accommodate the additional entries.
Under normal workloads, this is not a problem. Checkpoints complete regularly, the queue remains relatively small, and the underlying memory allocation never grows significantly.
The situation changes under sustained write-heavy workloads, particularly when shared_buffers is large enough to accumulate a substantial number of dirty pages before a checkpoint begins.
The chain of events looks like this:
- More dirty buffers accumulate in shared memory.
- More dirty buffers translate into more data files that must be flushed.
- More files require fsync() operations.
- More pending fsync() operations result in more entries being added to the fsync request queue.
- The queue continues to grow, forcing PostgreSQL to repeatedly resize its underlying memory structure.
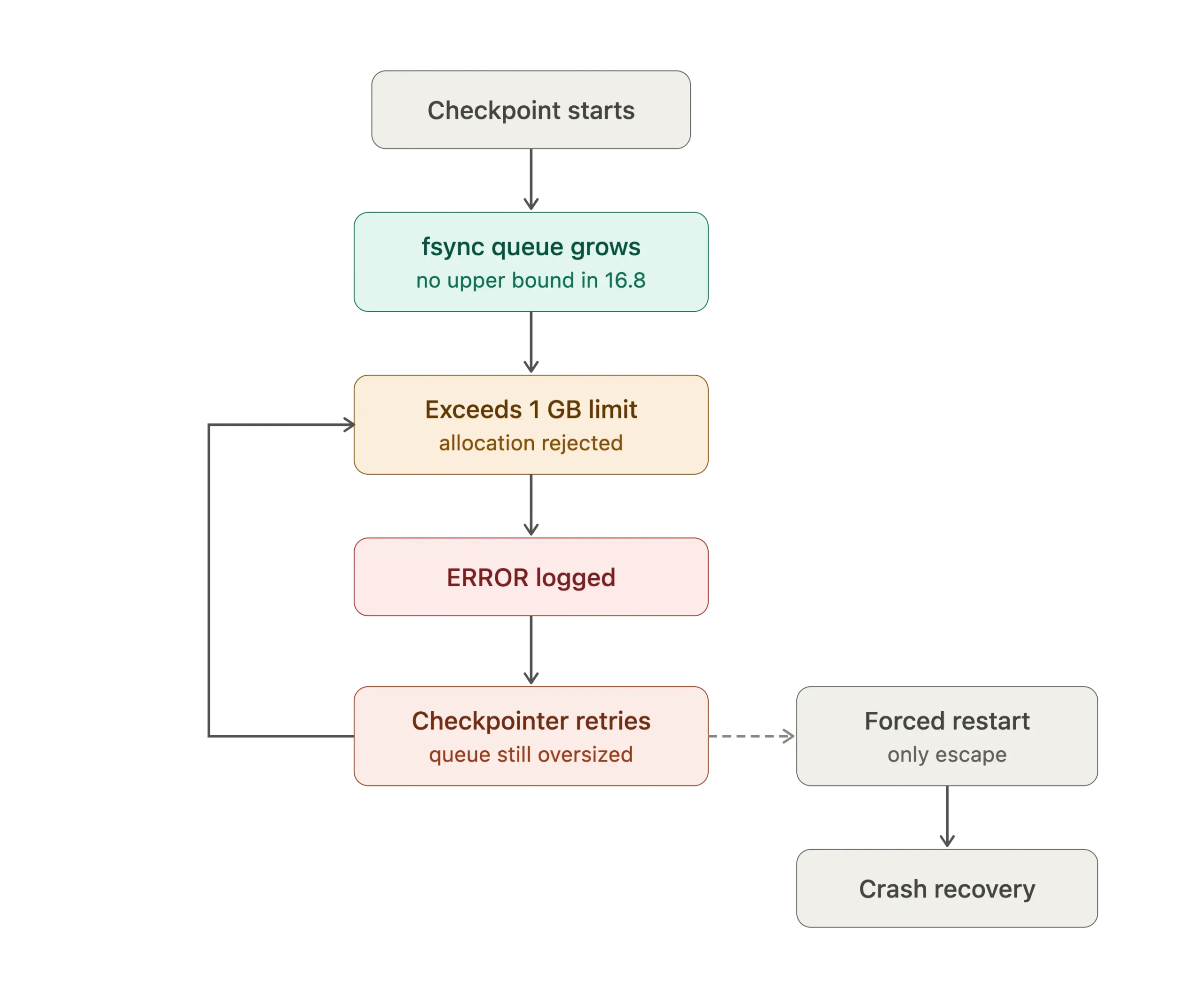
Up through PostgreSQL 16.8, there was no upper bound on the size of this queue. Under the right workload conditions, it could continue growing until PostgreSQL attempted to allocate a single contiguous block of memory larger than its own internal allocation limit, which is approximately 1 GB.
Importantly, this limit is not determined by the amount of RAM available on the system. It is an internal safeguard enforced by PostgreSQL’s memory manager to prevent excessively large allocations. Once a single allocation exceeds that limit, PostgreSQL rejects the request, regardless of how much physical memory remains available.
Queue As An Infinite Retry Loop
When the allocation failed in our environment, the checkpointer responded exactly as it was designed to. Instead of terminating, it caught the error and retried the operation. The problem was that this wasn’t a transient failure. Each retry encountered the same oversized fsync request queue, attempted the same memory allocation, and hit the same ceiling because nothing about the queue had changed between attempts.
The loop was self-sustaining and had no exit condition. In pg_stat_activity, the checkpoint process remained active for more than four hours without completing. The natural first response was to terminate it and issue a manual CHECKPOINT. That made no difference. A manually issued checkpoint uses the same checkpointer infrastructure and the same fsync request queue, so it encountered the same allocation failure immediately.
Meanwhile, the situation was quietly getting worse. Dirty pages remained in shared memory, the WAL kept growing, and the gap between the last successful checkpoint and the present widened with every passing minute. That gap matters because it directly determines how much WAL PostgreSQL has to replay if the instance is ever restarted uncleanly.
The Last Resort: Restart
With the checkpointer trapped in an unrecoverable retry loop, a forced restart of the PostgreSQL pod became the only remaining option. A graceful shutdown was no longer possible because checkpoint processing could not complete.
That distinction is important because during a normal shutdown, PostgreSQL completes a final checkpoint, flushes dirty buffers to disk, and leaves the database in a consistent state. A forced termination skips all of those steps. On the next startup, PostgreSQL detected the unclean shutdown and automatically entered crash recovery before accepting client connections.
Crash recovery begins from the last completed checkpoint and replays every WAL record generated after it until the database reaches a consistent state. In our case, the last successful checkpoint was already several hours old because the checkpointer had been stuck for so long. As a result, PostgreSQL had to replay several hours’ worth of WAL before the database could become available again, extending the outage for every dependent application.
The Upstream Fix
This issue had already been identified by the PostgreSQL community and was fixed in PostgreSQL 16.10, with the patch backported to all supported releases as far back as PostgreSQL 13.
The backported fix is intentionally small and low risk. Rather than redesigning the checkpointer, it simply places a hard upper bound on the size of the fsync request queue, limiting it to 10 million entries.
Before this change, the queue size was derived directly from NBuffers and therefore scaled with shared_buffers. As shared_buffers increased, so did the maximum size of the queue, with no safeguard to prevent it from eventually exceeding PostgreSQL’s internal allocation limit.
The fix changes that behavior by clamping the queue to a maximum of 10 million entries, regardless of how large shared_buffers is configured. Because each queue entry is a small fixed-size structure, even the maximum-sized queue remains comfortably below PostgreSQL’s 1 GB per-allocation limit. As a result, the oversized allocation that triggered the checkpointer failure can no longer occur.
The commit message also notes that the PostgreSQL development branch received a more comprehensive redesign of this code path. For the supported stable branches, however, introducing a simple upper bound was considered the safest solution: it eliminates the allocation failure without requiring invasive architectural changes.
Incident Summary
Applying The Fix in Production
The permanent solution was to upgrade PostgreSQL from 16.8 to 16.10, which includes the upstream fix. Because this was a minor version upgrade, the on-disk data format remained compatible, so there was no need for:
- pg_upgrade
- pg_dump / pg_restore
- Creating a new data directory
The existing data directory remained unchanged; only the PostgreSQL binaries were replaced.
For our Kubernetes deployment, the upgrade process consisted of the following steps:
- Stop application writes.
- Scale down the PostgreSQL StatefulSet.
- Update the PostgreSQL container image from 16.8 to 16.10.
- Reuse the existing Persistent Volume Claim (PVC).
- Scale the StatefulSet back up.
After the upgrade, the cluster started normally using the new PostgreSQL binaries while continuing to use the existing data directory.
Temporary Mitigation
If an immediate upgrade is not possible, reducing shared_buffers can mitigate the issue by limiting the number of dirty buffers that accumulate before a checkpoint. Fewer dirty buffers generally mean fewer files requiring fsync(), which limits the growth of the fsync request queue and reduces the likelihood of hitting PostgreSQL’s internal allocation ceiling. However, this is only a workaround, not a fix. The underlying bug remains, and the vulnerable code path is unchanged until PostgreSQL is upgraded.
Lessons Learned
This incident reinforced several operational lessons.
- First, don’t assume that invalid memory alloc request size necessarily indicates physical memory exhaustion. In some cases, PostgreSQL is rejecting an internal memory allocation rather than reporting that the operating system has run out of RAM.
- Second, PostgreSQL minor releases are far more than security updates. They regularly include important stability and reliability fixes that can prevent exactly this kind of production incident. Staying current with maintenance releases should be treated as routine operational hygiene rather than an optional upgrade.
- Third, checkpoint behavior deserves the same level of monitoring as query performance or replication lag. A checkpoint that remains active for an unusually long time can provide an early indication that something is wrong, long before it results in an outage.
Finally, if you’re running PostgreSQL 16.8 or 16.9, it’s worth reviewing the release notes and planning an upgrade.
Final Thoughts
This incident was a good reminder that error messages don’t always tell the full story.
What initially appeared to be a memory allocation problem turned out to be an edge case in PostgreSQL’s checkpoint implementation. An unbounded internal queue prevented checkpoints from completing, made manual recovery attempts ineffective, and ultimately left a restart as the only viable recovery option.
Fortunately, the fix was already available in a newer PostgreSQL maintenance release. The incident serves as a reminder that PostgreSQL minor releases often include important stability fixes in addition to security updates. Staying current with maintenance releases can prevent production issues that are difficult to anticipate and even harder to diagnose.
Our PostgreSQL Upgrade With Zero Downtime Service helps teams plan and execute minor and major PostgreSQL upgrades with minimal disruption. From compatibility assessments and upgrade planning to testing, execution, and post-upgrade validation, we work alongside your team to ensure production databases stay current without unnecessary downtime or surprises.