AI agents are becoming increasingly capable at operational tasks: summarizing logs, analyzing query plans, identifying anomalies, and assisting with incident response. For databases in particular, this creates an obvious opportunity. Much of day-to-day troubleshooting follows repeatable workflows that lend themselves well to automation.
As someone who spends most of my time working with PostgreSQL, I don’t think the interesting question is whether an LLM can help analyze a slow database. It can. The harder question is how to make that useful in production without making it unsafe.
Production databases sit behind layers of controls, processes, and accountability. Access is granted carefully because mistakes are expensive. When an engineer investigates an incident, that trust comes from experience and clearly defined responsibilities. Extending those capabilities to an AI agent raises a different challenge: how do you give it enough access to be useful without giving it enough access to be dangerous?
That problem is exactly what Model Context Protocol (MCP) attempts to address. Rather than exposing a database directly to an LLM, MCP introduces a layer of controlled capabilities. Instead of unrestricted access, the model receives a set of predefined tools with well-defined boundaries.
The LLM performs the reasoning. The server performs the measurements.
I’ve been experimenting with AI-assisted PostgreSQL troubleshooting for some time, and one project that stands out is postgres-mcp. It combines deterministic diagnostics, workload analysis, and access controls in a way that makes AI assistance practical without removing the human from the loop.
Before diving into the implementation, consider a familiar scenario. A production database starts running slowly, and the investigation usually begins with the same checklist:
- Active queries
- Wait events
- Locks
- Buffer cache hit rate
- Table and index bloat
- Vacuum status
- Slow queries from pg_stat_statements
- Missing indexes
The actual root cause may differ, but the process is remarkably consistent. These are repeatable, predefined steps, and repeatable workflows are excellent candidates for automation.
Collecting this information was never the hard part. A script can gather metrics and dump them into a file. The difficult part is analysis. During an incident, manually checking logs and jumping between seven different views is what consumes time.
The more interesting question is whether an AI agent can perform that analysis reliably without giving it the ability to drop tables. That’s the problem this article explores, and postgres-mcp is one of the more thoughtful attempts I’ve encountered.
What is MCP?
Model Context Protocol (MCP) is an open standard, originally introduced by Anthropic, that allows AI agents to interact with external systems such as PostgreSQL, Jira, and other applications through a common interface.
Before MCP, every agent required its own integration for every tool. A Postgres integration built for Claude didn’t work in Cursor, and neither worked in an in-house agent. Every new combination meant another piece of glue code. This is the classic N × M integration problem.
MCP reduces that complexity. A single MCP server can expose PostgreSQL functionality once, and every MCP-compatible client, Claude Desktop, Cursor, Windsurf, Goose, or an internal agent, can use it.
MCP terminology
Three components are worth distinguishing:
- Host: the AI application you’re interacting with.
- Client: the communication layer inside the host.
- Server: the component exposing functionality. postgres-mcp itself is a server.
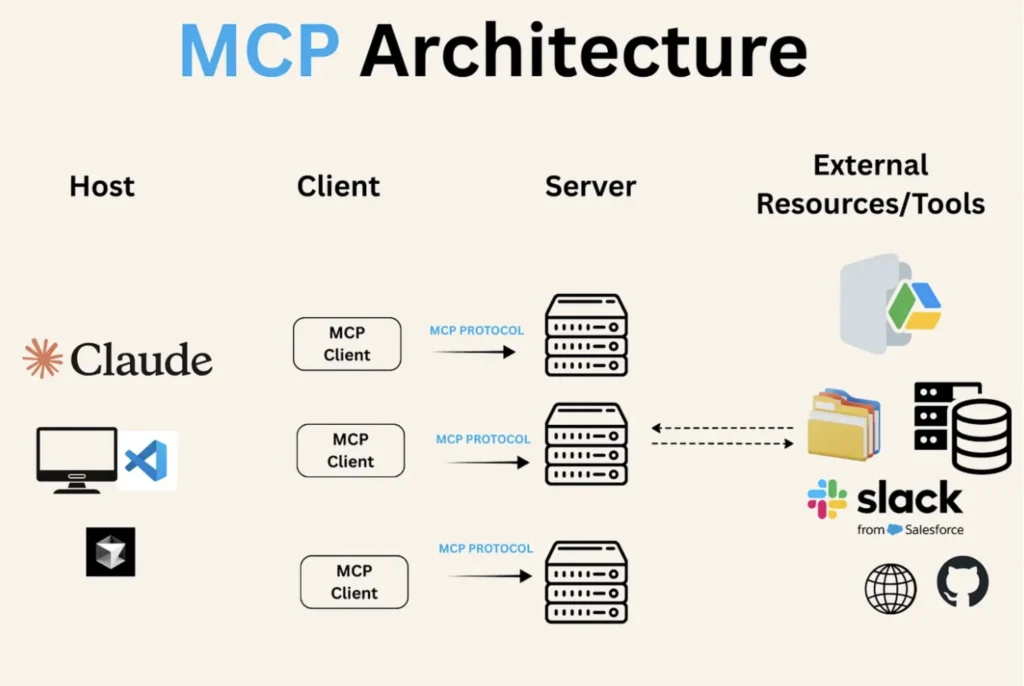
Image source: Medium
An MCP server exposes three kinds of capabilities:
- Tools: functions the model can invoke.
- Resources: information the model can read.
- Prompts: reusable templates.
Aside: MCP commonly uses JSON-RPC underneath. It’s simply a request-response protocol over plain text. Boring plumbing is often good plumbing.
Why MCP Matters for Databases
An obvious question is: if models already generate SQL reasonably well, why not simply give the agent a connection string? There are four problems with that approach.
- Determinism. Ask an LLM to “check database health” using raw SQL, and it may generate slightly different queries each time. That makes results difficult to compare over time.
- Granularity. A connection that can read often can write as well. The distance between SELECT and DROP TABLE is one hallucination away.
- Resource control. An innocent query missing an index may spend forty minutes scanning a large table. Nothing about a raw connection prevents that.
- Credential handling. Connection strings often end up pasted directly into prompts or configuration files.
A purpose-built MCP server addresses all four. It exposes a fixed set of capabilities and enforces boundaries in code rather than relying on prompt instructions.
If there’s one idea worth remembering, it’s this: the model does the reasoning, the tools do the measuring.
An Interaction Looks Like
Suppose you ask: “Check the health of my database.” The model inspects the available tools, discovers analyze_db_health, and decides to invoke it. That decision is the only AI component so far.
The request travels over JSON-RPC to the server. The server executes a fixed set of diagnostic queries — written and reviewed by humans, not SQL generated on the fly. Structured results come back, not prose. Only then does the model contribute: it interprets those measurements, prioritizes issues, and explains them in plain English.
It doesn’t see “the database is healthy.” It sees numbers. If the buffer cache hit ratio is 0.94, the model has to determine whether that represents a problem for the workload. Everything else in this MCP follows the same pattern: deterministic measurement performed by the server, with interpretation delegated to the model.
Access Modes
postgres-mcp supports two access modes.
Unrestricted mode provides full read-write access. That’s perfectly reasonable for development environments, where creating tables, loading test data, and modifying schemas are part of the workflow. Production environments are different.
Restricted Mode
Restricted mode is where things become interesting. Every statement executes inside a read-only transaction:
BEGIN TRANSACTION READ ONLY;
-- your statement
COMMIT;
At the database level, PostgreSQL itself rejects INSERT, UPDATE, DELETE, and DDL statements. At first glance, that sounds sufficient but it isn’t.
The multi-statement problem. Consider this input:
ROLLBACK;
DROP TABLE customers;
The ROLLBACK ends the read-only transaction, and the subsequent DROP TABLE executes in a new default transaction, bypassing the protection entirely. The fence has a gate, and this string walks straight through it.
Grammar-level validation with pglast. To address this, postgres-mcp adds a second layer: before execution, SQL is parsed using pglast, which relies on PostgreSQL’s actual grammar rather than regular expressions, and anything containing transaction control statements gets rejected. Conceptually, the logic looks like this:
from pglast import parse_sql
from pglast.enums import NodeTag
BLOCKED = {NodeTag.TransactionStmt}
def is_safe(sql: str) -> bool:
try:
stmts = parse_sql(sql)
except Exception:
return False
return not any(
stmt.stmt.node_tag in BLOCKED
for stmt in stmts
)
This example illustrates the approach rather than the exact implementation. The important distinction is that validation happens at the grammar level and it isn’t a simple search for the word “rollback.”
Execution time limits. There’s a third layer as well. Integrity isn’t the only concern; availability matters too. A query that monopolizes a connection for forty minutes is its own production incident, even if it never writes a byte. Execution time limits provide another layer of defense.
One important caveat. The project documents an important limitation: unsafe procedural languages could theoretically bypass some of these protections. Plain PL/pgSQL is safe in this context, it cannot issue transaction control commands inside a function, but other languages deserve scrutiny. It’s worth knowing exactly what’s enabled in a database:
SELECT lanname FROM pg_language;This is an example of defense in depth with clearly documented boundaries rather than security by assumption.
Health Checks
Health checks are arguably the most useful capability in postgres-mcp. They automate many of the checks experienced PostgreSQL engineers already perform during incidents. These checks are largely adapted from PgHero rather than invented from scratch, and the tool can be used both as a routine health assessment and during production incidents.
1- Index health. Indexes that are duplicated, bloated, or never used increase write overhead without providing any benefit.
SELECT
schemaname,
relname,
indexrelname,
idx_scan
FROM pg_stat_user_indexes
WHERE idx_scan = 0
AND indexrelname NOT LIKE '%_pkey';
Unused indexes quietly make every write more expensive.
2- Buffer cache. The buffer cache hit ratio is one of the best indicators of real-world latency.
SELECT
sum(heap_blks_hit) /
nullif(sum(heap_blks_hit) + sum(heap_blks_read),0)::float AS hit_ratio
FROM pg_statio_user_tables;
As rough guidelines, below 99% deserves investigation for OLTP workloads, and below 90% usually means the working set no longer fits inside shared_buffers.
3- Connections. Connection pressure matters, and so do sessions sitting idle inside transactions.
SELECT
count(*) AS total,
count(*) FILTER (
WHERE state = 'idle in transaction'
) AS idle_in_txn,
(
SELECT setting::int
FROM pg_settings
WHERE name = 'max_connections'
) AS max_conn
FROM pg_stat_activity;
The default value for max_connections is 100. Idle transactions deserve particular attention because they hold resources and interfere with vacuum.
4- Vacuum status. PostgreSQL transaction IDs are finite, and without vacuum, wraparound eventually stops the database from accepting writes.
SELECT
datname,
age(datfrozenxid) AS xid_age
FROM pg_database
ORDER BY xid_age DESC;
Some important thresholds: transaction IDs wrap around near 2.1 billion (2^31), and autovacuum_freeze_max_age defaults to 200 million, so PostgreSQL forces aggressive vacuuming long before the danger zone. Wraparound incidents are rare, but they are among the most serious failures a database can experience.
5- Replication. Replication checks examine both lag and abandoned replication slots.
SELECT
slot_name,
pg_wal_lsn_diff(
pg_current_wal_lsn(),
restart_lsn
) AS retained_bytes
FROM pg_replication_slots
WHERE NOT active;
Unused replication slots can quietly consume disk space until WAL retention becomes a problem.
6- Constraints. Failed migrations or bulk loads sometimes leave constraints invalid.
SELECT
conname,
conrelid::regclass AS table_name
FROM pg_constraint
WHERE NOT convalidated;
An invalid constraint is dangerous because it creates the illusion that data is protected when it isn’t.
7-Sequences. Sequence exhaustion tends to become visible only when it’s too late.
SELECT
seqrelid::regclass AS sequence_name,
last_value,
max_value,
round(
100.0 * last_value / max_value,
1
) AS pct_used
FROM pg_sequences
WHERE last_value::float / max_value > 0.75;
For integer, the maximum value is 2,147,483,647. Detecting usage at 75% provides enough runway to plan a migration to bigint rather than dealing with an outage. None of these checks are particularly novel, and that’s the point. They represent decades of operational experience encoded into deterministic queries. The model isn’t inventing diagnostics — the server is performing known measurements, and the model’s job is simply to prioritize and explain the results.
Workload Analysis and the Index Problem
In practice, missing indexes are among the most common causes of poor PostgreSQL performance. The workload analysis capabilities in postgres-mcp are primarily concerned with finding those missing indexes.
The process starts with pg_stat_statements. Slow queries are collected and normalized so that the same query template is counted once rather than treating each set of parameters as a separate query. From there, the server examines WHERE clauses, join conditions, and GROUP BY columns. These become candidate indexes.
The Combinatorial Explosion Problem
Single-column indexes are straightforward. Multi-column indexes are not. Once combinations are considered, the number of possible indexes grows rapidly — a moderately complex workload can easily produce thousands of candidates. Creating thousands of physical indexes simply to evaluate them isn’t practical. Even a single CREATE INDEX on a large table may consume significant I/O, take minutes to complete, increase write overhead, and require substantial storage. Fortunately, PostgreSQL has a better option.
Hypothetical indexes with hypopg. Instead of physically building indexes, postgres-mcp relies on hypopg. For example:
SELECT *
FROM hypopg_create_index(
'CREATE INDEX ON orders(customer_id, created_at)'
);
EXPLAIN
SELECT *
FROM orders
WHERE customer_id = 42
AND created_at > now() - interval '30 days';
SELECT hypopg_reset();
These indexes don’t exist physically. They consume almost no resources, but PostgreSQL’s planner can still evaluate them using its normal cost model. This allows thousands of possibilities to be explored without paying the cost of building real indexes.
The Anytime Algorithm
The search strategy used by postgres-mcp is adapted from the Anytime Algorithm originally used by Microsoft’s SQL Server tuning advisor. The process is greedy — it proceeds one index at a time: find the best single index, add the next most valuable index, re-evaluate, and continue until time expires or improvements become insignificant. Exploration stops when a round fails to achieve at least a 10% improvement. This provides a good balance between search quality and computational cost.
Choosing Between Performance and Storage
Indexes improve performance, but they consume storage and increase write costs. When two candidates compete, postgres-mcp selects a point on the Pareto frontier using a logarithmic rule:
log10(performance_improvement) ≥ 2 × log10(storage_cost_increase)This creates an intentionally asymmetric tradeoff: a 100× speedup justifies roughly a 10× increase in storage, while a 10× speedup only justifies around a 3.2× increase. Most engineers would happily accept the first tradeoff but reject the second, and the algorithm reflects that intuition instead of treating every storage increase equally.
Experimental LLM-Based Search
An experimental mode replaces the heuristic search with an LLM. The process works as follows: schema information and plans are sent to the model, the model proposes candidate indexes, hypopg evaluates them, scores are returned to the model, and the loop repeats until improvements plateau. This mode requires an OPENAI_API_KEY, and it’s positioned as an alternative when the search space becomes too large for the heuristic approach, not as a replacement for it.
The prerequisites for any of this are straightforward:
CREATE EXTENSION IF NOT EXISTS pg_stat_statements;
CREATE EXTENSION IF NOT EXISTS hypopg;
From there, the interaction can be surprisingly simple: “Analyze my database workload and suggest indexes to improve performance.” The complexity lives inside the server, not in the prompt.
Limitations
No tool is perfect, and it’s worth understanding where the boundaries are.
- Prompt injection through data. The agent reads data, and data ultimately comes from users, which means data itself becomes part of the model’s context. A comment field, description, or free-form text column can contain unexpected content that influences model behavior. Prompt injection isn’t limited to prompts as data can carry it too.
- The interpretation layer is probabilistic. The measurements are deterministic, but the interpretation isn’t. Statistics, system catalogs, and query plans come directly from PostgreSQL, so those values are exact. The explanation layered on top, however, is generated by a language model, and language models can be confidently wrong. If the model claims something is critical, treat that as a recommendation rather than a fact, and review conclusions before escalating incidents, sending reports to clients, or making production changes.
The goal isn’t to remove engineers from the process; it’s to offload repetitive work so that people can spend time making decisions. A useful mental model is to think of the agent as a junior DBA: a very fast, very well-read junior DBA. It excels at gathering information, running diagnostics, surfacing anomalies, and performing groundwork, and it’s available twenty-four hours a day. But occasionally, it’ll be confidently wrong, which means the work still needs review. Used that way, these systems are already remarkably high-leverage.
Deployment Issues
Most deployment challenges are operational and are often the issues that bite people in practice.
- pg_stat_statements requires a restart. On self-managed PostgreSQL, pg_stat_statements must appear in shared_preload_libraries, which means a restart. Managed services usually require a parameter group change followed by a reboot. This applies to RDS, Cloud SQL, and Azure Database for PostgreSQL. It’s much better to plan for this ahead of time than discover it in the middle of an incident.
- Credential management. The DATABASE_URI exists in plaintext somewhere, in practice, that usually means configuration files, environment variables, or developer laptops, and many MCP clients still have immature secret handling. Treat the database credential like any other service account: create a dedicated role, follow least privilege, and rotate credentials periodically.
- Shared credentials under SSE. With SSE deployments, multiple users connect to the same server, which means the database sees one identity. Audit logs effectively collapse into “mcp-user did this,” and individual accountability disappears. That’s a tradeoff worth understanding before deploying shared servers.
- Large schemas consume context. Against a schema containing hundreds of tables, naive discovery can overwhelm the model’s context window — a 500-table database may consume enormous amounts of tokens before useful analysis even begins. It often helps to guide the agent toward the relevant schema first.
- PgBouncer caveats. Transaction pooling deserves special attention, since PgBouncer assigns a different physical connection for every transaction, and session-scoped state doesn’t survive across those boundaries. That affects the read-only wrapper used in restricted mode and the hypothetical indexes created by hypopg. For this reason, it’s often better to give the MCP server its own direct PostgreSQL connection.
- Planner statistics matter. hypopg relies on PostgreSQL’s planner, and the planner relies on statistics; bad statistics produce bad recommendations. Before running tuning sessions, run ANALYZE;, and before touching production, validate recommendations in staging, measure actual performance improvements, and confirm that indexes are being used.
- One server per database. Today, postgres-mcp binds to a single DATABASE_URI during startup, which means one server instance per database and one container per database. Several databases on the same cluster still require several server instances; it’s a limitation of the current architecture rather than PostgreSQL itself.
Trying It Yourself
postgres-mcp can be run in several ways, but Docker is probably the easiest starting point. You choose the transport (stdio or SSE) and the access mode (restricted or unrestricted). For most production environments, restricted mode is the sensible default.
Once the server is running and connected to your preferred MCP client, interaction becomes conversational. You can start with simple questions, like what schemas exist, or asking to see the tables in the public schema, or to describe the orders table.
Then move into operational tasks: perform a health check on the database, ask what to investigate if it’s running slowly, show the most expensive queries, analyze the workload and recommend indexes, or estimate how much those indexes would help before creating them. After implementing an index recommendation, you can ask it to re-check the query and confirm whether the index is being used.
And if you’d like to see the safety model in action, test this in restricted mode:
ROLLBACK;
DROP TABLE customers;
In restricted mode, this is precisely the kind of input the pglast layer is designed to reject.
Frequently Asked Questions
Does Restricted Mode Protect Confidentiality?
No. Restricted mode is an integrity control, not a confidentiality control. The agent can still read whatever data the database role allows it to access. If confidentiality is the concern, the solution is still the traditional toolbox: least-privilege roles, column-level privileges, row-level security, and restricting which databases the agent can access. An AI agent can’t leak data it never sees.
How Is This Different from pgAnalyze or Postgres.ai?
Products such as pgAnalyze and Postgres.ai provide complete platforms with dashboards, monitoring, and their own user experience. postgres-mcp solves a different problem as it’s an open protocol server that brings those capabilities into whichever AI tools your team already uses: Claude, Cursor, Windsurf, Goose, or internal agents. They’re complementary rather than competing approaches.
Why Not Just Give an LLM a Connection String?
Because SQL generation and database operations are fundamentally different problems. A raw connection provides no determinism, no capability boundaries, no resource limits, and weak credential handling. MCP introduces structure: the model decides what to do, and the server determines how it gets done.
Does This Replace DBAs?
No. The goal is to automate repetitive work. Experienced engineers still provide context, judgment, risk assessment, and decision-making. The model helps with analysis; humans remain responsible for decisions.
Key Takeaways
Several ideas stand out:
- MCP is becoming a standard integration layer. MCP provides a common interface between AI agents and external systems. Instead of building separate integrations for every tool and every client, functionality can be exposed once and reused across the ecosystem.
- Determinism matters. The server performs deterministic measurements, and the model performs interpretation. That separation is important — it makes results reproducible while still benefiting from the flexibility of LLMs. The model does the reasoning; the tools do the measuring.
- Health checks are an excellent first use case. Database troubleshooting often follows repeatable workflows. Encoding those workflows into deterministic tools makes AI assistance practical without sacrificing control, and health checks are probably the lowest-risk and highest-value place to begin.
- Restricted mode should be the default. For production systems, use restricted mode, use a read-only database role, apply least privilege, and treat credentials like service accounts. Safety shouldn’t depend on prompt wording — it should be enforced in code.
- Keep a human in the loop. AI agents excel at gathering information, running diagnostics, finding patterns, and surfacing anomalies. They’re less good at understanding business context, assessing risk, and making final decisions. Think of them as very capable assistants rather than autonomous operators.
Closing Thoughts
What I find interesting about postgres-mcp isn’t that it adds AI to PostgreSQL — plenty of projects do that. What’s interesting is the architecture. Instead of asking the model to improvise SQL and hoping for the best, the project deliberately separates deterministic measurement from probabilistic reasoning. Proven algorithms, PostgreSQL internals, and decades of operational knowledge remain responsible for gathering facts. The language model’s role is interpretation and explanation.
That division of responsibilities feels much closer to how AI systems should interact with production infrastructure. The interesting question was never whether LLMs could help troubleshoot databases; they clearly can. The harder question is how to do that safely. postgres-mcp is one answer to that question, and perhaps more importantly, an example of a design pattern that will likely become increasingly common as AI systems gain access to operational tooling.
If you’d like to experiment with it yourself, the project is open source at crystaldba/postgres-mcp.