PostgreSQL, often through platforms like Lovable, is increasingly becoming part of the default stack for many AI applications. That level of adoption says something important about where engineering teams are placing their trust.
PostgreSQL didn’t have to reposition itself as an “AI database” for this to happen. The characteristics that made it reliable for traditional applications also made it a natural fit for AI workloads. As more AI products move into production, engineering teams are starting to spend more time thinking about how PostgreSQL behaves under concurrency, how vector workloads scale, and how operational ownership changes once usage grows.
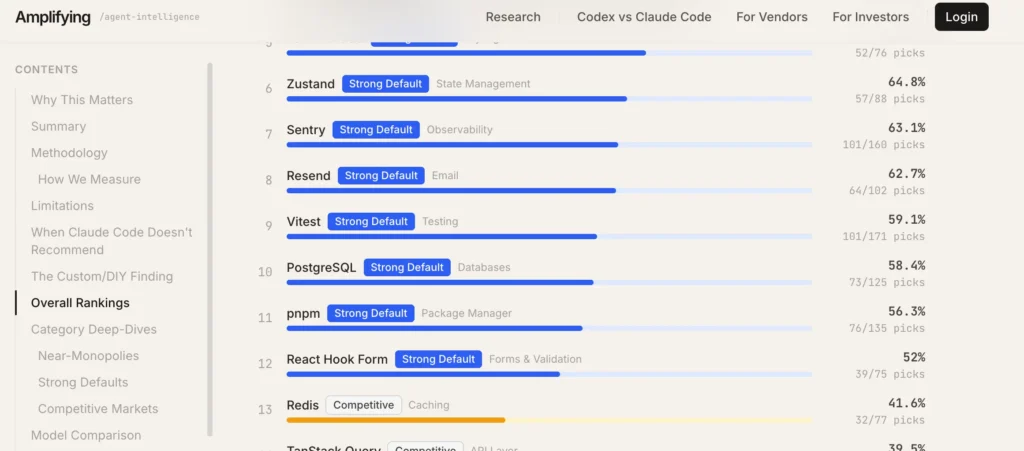
How PostgreSQL became deeply embedded in AI infrastructure
PostgreSQL has been in continuous development since the POSTGRES project began at UC Berkeley in 1986. Over decades, it matured into a database known for transactional reliability, extensibility, replication, and operational stability. That extensibility became especially important for AI applications.
The pgvector extension allows embeddings and similarity search to live inside PostgreSQL alongside transactional application data. For many teams, this keeps the architecture simpler. Instead of introducing a separate vector database, embeddings can be stored and queried inside infrastructure the team already understands and operates.
Lovable accelerated adoption even further. Because Lovable is built on Supabase, every Lovable project effectively creates a PostgreSQL deployment underneath. As Lovable gained traction during the rise of “vibe coding” and AI-assisted application development, PostgreSQL naturally became embedded deeper into the AI development ecosystem at scale.
The surrounding ecosystem reinforced this direction with major AI frameworks supporting PostgreSQL integrations directly, cloud providers offering mature managed PostgreSQL services, and ORMs prioritizing PostgreSQL support early. For many engineering teams, PostgreSQL became the most practical operational path.
What changes once AI workloads grow
Most AI applications begin with relatively small workloads. Query latency is manageable, embedding counts are limited, and infrastructure remains lightly utilized.As products grow, the workload changes significantly. Vector search performance changes as embedding datasets increase in size. Indexing strategies that worked comfortably during development begin behaving differently under larger datasets and higher concurrency. Workloads generated by retrieval pipelines, asynchronous inference calls, and hybrid search patterns place different pressure on the database than traditional application traffic.
The operational symptoms usually appear gradually:
- Connection spikes during concurrent inference activity
- Vector indexes growing faster than expected
- Latency becoming inconsistent under load
- Replication lag increasing on replicas during write-heavy traffic
- Memory pressure increasing as embedding workloads expand
Connection management also becomes more important. AI applications frequently generate multiple concurrent database interactions per request, which increases pressure on PostgreSQL connections and memory usage. Teams that previously never thought about PgBouncer or Supavisor often begin evaluating pooling strategies once concurrency increases.
Monitoring patterns evolve as well. Traditional dashboards focused on transactional query latency do not always surface vector index behaviour, embedding search latency, or retrieval-specific bottlenecks early enough.
PostgreSQL continues to support the workload, but the database begins requiring a higher level of operational ownership than most teams anticipated at the prototype stage.
The operational gap
A pattern appears frequently in growing engineering organizations. The application succeeds, AI features gain adoption, and product velocity remains high. At the same time, very few people inside the organization have deep familiarity with PostgreSQL behaviour under sustained production pressure.
This remains manageable for a long time because PostgreSQL is resilient and forgiving. Eventually the workload reaches a point where database behaviour becomes more visible. A large customer onboarding, increased concurrency, heavier retrieval patterns, or rapid product growth begins exposing operational assumptions that were never revisited.
At that stage, engineering teams often realize the database requires more deliberate ownership than it did earlier. This ailment is not unique to AI applications and AI workloads simply accelerate the pace at which these operational questions surface.
PostgreSQL’s future in AI
There is ongoing discussion around whether LLMs and retrieval systems may eventually reduce the importance of structured databases. In practice, AI applications still rely heavily on transactional consistency, concurrent writes, access control, auditability, and reliable operational systems underneath the AI layer.
As applications move beyond simple prototypes and into production environments with multiple users, transactional guarantees and operational reliability become increasingly important. PostgreSQL continues expanding into this environment through pgvector adoption, integration across AI tooling, and broader ecosystem support.
The increasing use of PostgreSQL across AI applications reflects how engineering teams are choosing to build operational systems around AI products today.
What engineering teams should think about early
PostgreSQL operational debt tends to accumulate quietly but with AI applications, the workload changes faster than most teams expect. This usually becomes visible through recurring operational pressure such as:
- The same performance issues resurfacing under scale
- Uncertainty around failover behaviour during traffic spikes
- Engineers spending increasing time investigating query behaviour
- Infrastructure costs rising faster than workload growth
- Growing hesitation around upgrades or architectural changes
The challenge is rarely PostgreSQL itself and is mostly operational maturity that evolves more slowly than the workload. AI applications accelerate that pressure because concurrency, vector search, and retrieval-heavy traffic introduce workload characteristics many teams have not previously operated at scale. At a certain point, PostgreSQL stops being background infrastructure and becomes an active operational responsibility for the team.
That shift is becoming increasingly common as PostgreSQL becomes part of the operational foundation underneath AI products. The teams that continue to operate it successfully as workloads grow are usually the ones that revisit architecture, workload behaviour, and operational ownership before pressure forces those conversations. PostgreSQL itself continues to scale well. The difference comes from how deliberately the system evolves alongside the product using it.
