Modern applications heavily rely on ORMs (Object-Relational Mappers) for rapid development. While ORMs accelerate development, they often generate queries that are not fully optimized for database performance. In such environments, database engineers have limited control over query structure, leaving indexing and database tuning as the primary performance optimization tools.
In this article, I’ll share how we improved PostgreSQL performance dramatically for one of our enterprise customers by applying strategic indexing techniques,without modifying application queries.
The Challenge: High Read IOPS and Slow Query Performance
One of our customers experienced severe performance degradation, including:
- High Read IOPS on the database
- Slow page loads and delayed reports
- Increasing database load during peak hours
After analyzing PostgreSQL configuration parameters, we confirmed that:
- Memory parameters were properly tuned
- Autovacuum was functioning correctly
- Hardware resources were sufficient
However, performance issues persisted.
Since the application relied entirely on ORM-generated queries, rewriting queries was not an option. We needed a solution at the database level.
Root Cause Analysis: Excessive Sequential Scans
We analyzed PostgreSQL statistics using:
- pg_stat_user_tables
- pg_stat_user_indexes
- pg_constraint
- pg_index
We discovered extremely high sequential scans on large tables—some exceeding 41 million scans.
Sequential scans on large tables significantly increase disk I/O and slow query execution.

The primary reason: Missing indexes on foreign key columns and frequently filtered columns.
Strategy #1: Foreign Key Index Optimization
Why this matters
PostgreSQL does NOT automatically create indexes on foreign key columns.
Without these indexes, PostgreSQL must perform sequential scans when:
- Joining tables
- Filtering by foreign keys
- Enforcing referential integrity
This is especially critical in ORM-based systems, where joins on foreign keys are extremely common.
How we identified missing FK indexes
We ran the following query to detect missing indexes on foreign key columns in large, frequently scanned tables:
WITH high_seq_tables AS (
SELECT
st.relid,
st.schemaname,
st.relname AS table_name,
st.seq_scan,
pg_total_relation_size(st.relid) AS table_size_bytes
FROM pg_stat_user_tables st
WHERE st.seq_scan > 10000
AND pg_total_relation_size(st.relid) >= 524288000
),
fk_columns AS (
SELECT
con.conrelid,
att.attname AS fk_column
FROM pg_constraint con
JOIN unnest(con.conkey) AS colnum(colnum) ON true
JOIN pg_attribute att
ON att.attrelid = con.conrelid
AND att.attnum = colnum.colnum
WHERE con.contype = 'f'
),
fk_index_check AS (
SELECT
fk.conrelid,
fk.fk_column,
NOT EXISTS (
SELECT 1
FROM pg_index idx
JOIN pg_attribute ia
ON ia.attrelid = idx.indrelid
AND ia.attnum = ANY(idx.indkey)
WHERE idx.indrelid = fk.conrelid
AND idx.indisvalid
AND ia.attname = fk.fk_column
) AS is_missing_fk_index
FROM fk_columns fk
)
SELECT *
FROM fk_index_check
WHERE is_missing_fk_index = true;

Results after implementing FK indexes
After creating indexes on critical foreign key columns:
- Sequential scans reduced by over 87%
- Query response time improved by 60-80%
- Disk read IOPS dropped significantly
- Overall system responsiveness improved dramatically
This was the single most impactful optimization.
Strategy #2: Slow Query Driven Index Optimization
Instead of blindly indexing everything, we followed a targeted approach using slow query analysis.
Step 1: Enable Slow Query Logging
SET log_min_duration_statement = 420000;
This logs queries taking longer than 7 minutes. You can adjust this threshold based on your workload.
Step 2: Identify Query Patterns
From slow query logs, we identified common patterns:
Columns frequently used in:
- WHERE clauses
- JOIN conditions
- GROUP BY operations
- Aggregations (AVG, COUNT, SUM)
Step 3: Create Targeted Indexes
We created indexes on:
- Foreign key columns
- Join columns
- Filter columns
- Frequently aggregated columns
Example:
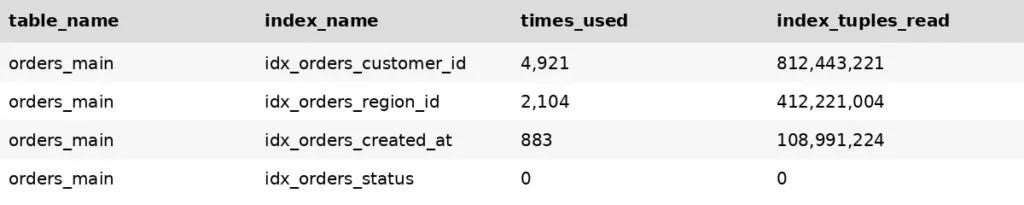
CREATE INDEX CONCURRENTLY idx_orders_customer_id ON orders_main(customer_id);Index Usage Validation
After creating indexes, we verified usage via:
SELECT *
FROM pg_stat_user_indexes
ORDER BY idx_scan DESC;
This helped ensure indexes were actually used and provided performance benefits.
Overall Performance Improvements
Metric | Improvement |
Sequential Scans | ↓ 87% |
Query Execution Time | ↓ 60–80% |
Disk Read IOPS | ↓ 70% |
Application Response Time | Dramatically Improved |
Key Lessons Learned
- Always index foreign key columns in ORM-driven applications
- Use PostgreSQL statistics views to identify missing indexes
- Enable slow query logging to identify optimization opportunities
- Create targeted indexes, not excessive indexes
- Continuously monitor index usage and performance
Final Thoughts
When application-level optimization is limited due to ORM constraints, database-level indexing becomes the most powerful performance optimization tool.
Strategic indexing can dramatically improve PostgreSQL performance without modifying application code or upgrading hardware.