High Availability & Disaster Recovery
Client Requirements
Understanding the client requirements is crucial before beginning the backup procedure. Depending on their operational requirements, every organization may have distinct backup and recovery objectives. Potential factors are explained below.
1. Recovery Point Objective (RPO)
The acceptable data loss threshold, specifying how much data the organization is willing to lose in the event of a disaster. It also helps you measure how long it can take between the last data backup and a disaster without seriously damaging your business. RPO is useful for determining how often to perform data backups.
For example, RPOs with very low values, such as less than one minute, might need continuous replication of critical files, databases, and systems. This is the RPO, to have backed up data as current as possible.

Another example is the scenario where you back up your data once a day at midnight (12:00 AM) and there is a disaster at 8:00 AM. In this case, you will lose 8 hours of data. If your RPO is 24 hours or more, you’re in good shape. But if your RPO is, say, four hours, you’re not.
2. Recovery Time Objective (RTO)
The target time within which the system should be recovered and operational after a failure.
For example, if you set your RTO as 2 hours, then you should be able to continue normal business operations within this timeframe in case of any disaster. If during real-life disaster recovery, you go over the given time frame, you should either reconsider the RTO calculations or update your disaster recovery plan and procedures.
To calculate RTO, we need to consider these factors:
- The cost per hour of outage.
- The importance and priority of individual systems.
- Steps required to recover from a disaster including restoration of individual components and processes.
- Available budget and resources.
The following figure depicts the RPO and its relationship to the RTO.
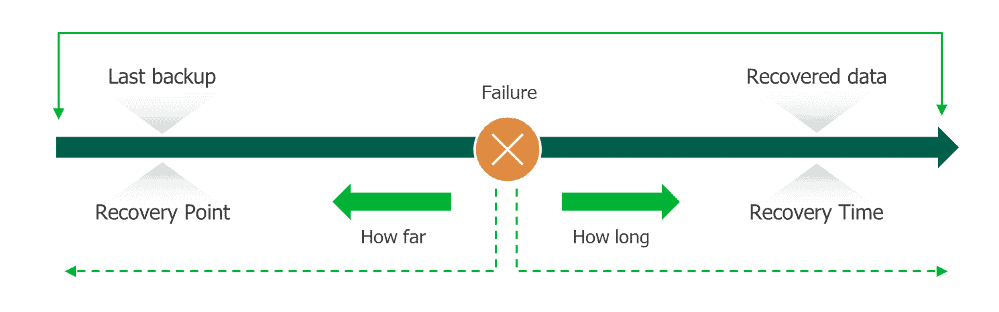
Image taken from Global Data Vault
3. Storage capacity
Determine the storage space required for backups based on the organization’s data growth rate and retention policy.
Business Use Case
Physical backups using pg_basebackup are suitable for various scenarios, including:
- Full system recovery after a catastrophic failure, such as hardware failure or data corruption.
- Migrating a PostgreSQL database to a different server or platform (base backup doesn’t provide major version migrations)
- Setting up a standby or replica server for high availability or load balancing purposes.
- Point in time recovery

