PostgreSQL High Availability Solutions
Elevating PostgreSQL for systems that demand consistency
PostgreSQL is built for data integrity and reliability. With the right expertise, it becomes a dependable core for mission-critical systems.
At Stormatics, we provide the specialised expertise required to unlock PostgreSQL’s full potential in production through highly available clusters created through deliberate architectural design, tested recovery paths, and operational discipline.
We design tailored PostgreSQL High Availability solutions, backed by robust SLA commitments that ensure 99.99% uptime. Using techniques like replication, auto-failover, and advanced clustering, we provide guaranteed performance and uptime. Our tailored HA strategies preempt the risk of database outages and deliver uninterrupted operations you can rely on.
Schedule a consultation to explore how your PostgreSQL environment can be engineered for continuous, dependable operations.

5 good reasons to invest in High Availability

Customer Success Story
99.99% Availability for PostgreSQL on MS Windows
The ecosystem supporting PostgreSQL is quite limited on Windows and that was the issue facing a critical government organization in the Middle East when they approached us.
This organization had moved from SQL Server to PostgreSQL and attempted to solve the high availability problem like they had done for their previous database – relying on the OS layer. This goes against best practices of setting up PostgreSQL clusters and is also highly unreliable – something the customer experienced firsthand when their database kept going down in production.
This was a challenging project, something that’s right up our alley. We enjoy solving the hard problems!
How we Ensure 99.99% Availability for PostgreSQL
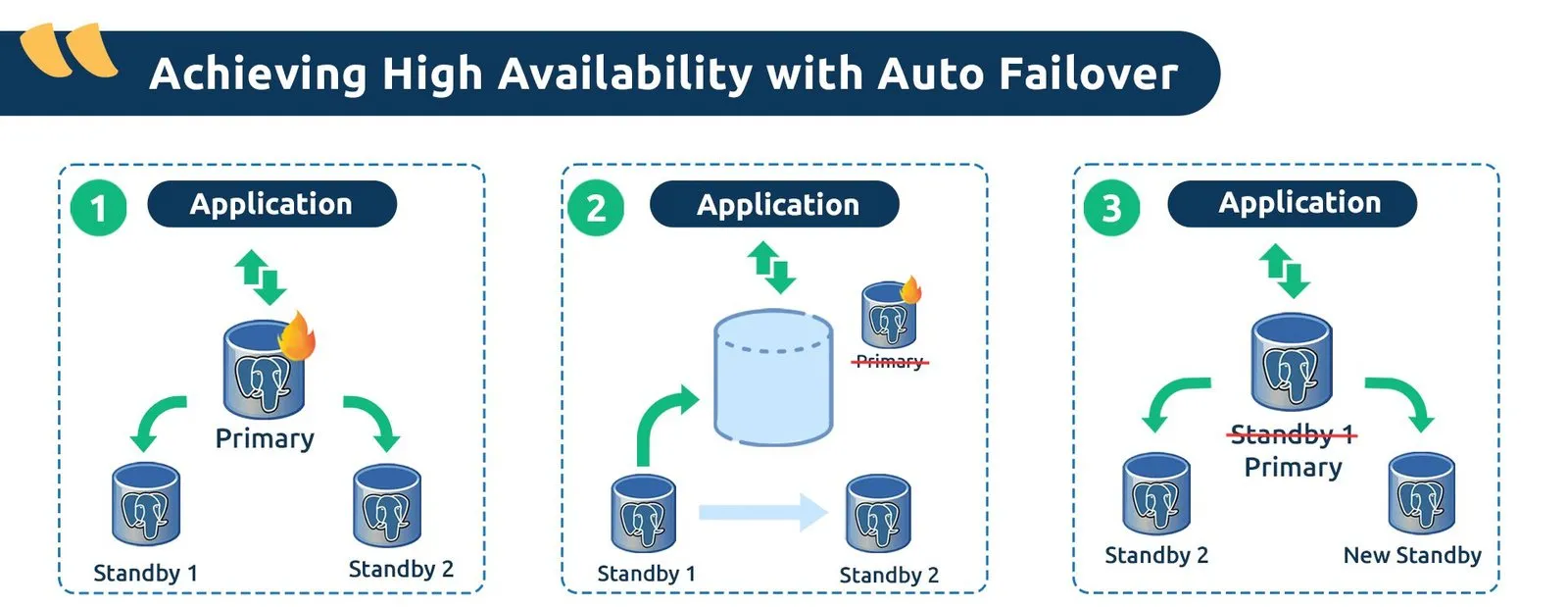
Our signature approach to PostgreSQL High Availability is built on a multi-node architecture with replication and automatic failover. This ensures your data is always secure and accessible when you need it. The entire process is fully automated, eliminating the need for human intervention and reducing the risk of errors during critical moments.
Frequently Asked Questions (FAQs)
Q. What does high availability mean?
High availability refers to the ability of a database system, such as PostgreSQL, to remain accessible and operational with minimal downtime. It is achieved by implementing redundancy, automated failover, and monitoring systems that ensure seamless service, even during failures.
Q. Does PostgreSQL have high availability?
Yes, PostgreSQL supports high availability by using clustering, replication, and failover mechanisms. These configurations ensure that PostgreSQL databases remain accessible, even during server failures, making it a reliable choice for critical applications.
Q. How to set up high availability in PostgreSQL?
To set up high availability in PostgreSQL, configure primary-secondary replication using tools like pgpool-II, Patroni, or repmgr. Implement synchronous or asynchronous replication to sync data between the primary and standby servers, ensuring seamless failover in case of primary server failure.
Q. How do you get high availability in a database?
You can achieve high availability in databases like PostgreSQL by setting up replication, clustering, and automated failover. Use monitoring tools to detect failures and trigger failover to standby servers, ensuring continuous service and minimal downtime.
Q. Is PostgreSQL suitable for big data with high availability requirements?
Yes, PostgreSQL is well-suited for highly available big data solutions. It supports large datasets and offers features like table partitioning, replication, and clustering to handle big data workloads while maintaining high availability.
Q. Do big companies use PostgreSQL with high availability?
Many large enterprises, including those in financial services, healthcare, and technology sectors, use PostgreSQL with high availability setups. It is a cost-effective, reliable, and scalable option that supports critical applications and ensures continuous database operations.
Q. Does PostgreSQL have automatic failover?
Yes, PostgreSQL supports automatic failover when integrated with tools like Patroni, repmgr, or pgpool-II. These tools monitor the primary server’s health and automatically promote a standby server to primary if a failure occurs, reducing downtime.
Q. What is the best practice for creating a highly available PostgreSQL?
Best practices include using asynchronous replication, setting up load balancers for traffic distribution, and implementing automated failover. Regular failover testing, monitoring, and maintaining sufficient server resources are also essential to ensure optimal performance and high availability.
Q. How do you create a highly available cluster?
To create a highly available PostgreSQL cluster, deploy multiple database instances, set up replication, and configure automatic failover using tools like Patroni or repmgr. Add load balancers to distribute traffic evenly and perform regular testing to ensure the cluster operates smoothly.
Q. What is the difference between hot standby and warm standby in PostgreSQL?
In PostgreSQL, a hot standby allows read-only queries on the standby server, helping distribute read loads. A warm standby, however, is purely for failover and does not accept queries until it becomes the primary server.
Q. What are the three main high availability strategies?
The three main high availability strategies for PostgreSQL are:
- Replication: Copies data between servers to ensure redundancy.
- Clustering: Combines multiple nodes into a single system for increased resilience.
- Automated Failover: Switches to standby servers automatically during failures.
Q. How do you ensure database availability?
You can ensure database availability by introducing redundancy. Setting up replication, automated failover, and load balancing are some of the steps you can take. Regular health checks, monitoring tools, and backups are also vital to maintain a highly available PostgreSQL environment.
Q. How do you measure high availability?
High availability is measured in ‘Nines of Availability’.
- 90% (one nine) – 36.53 days of downtime per year
- 99% (two nines) – 3.65 days of downtime per year
- 99.9% (three nines) – 8.77 hours of downtime per year
- 99.99% (four nines) – 52.60 minutes of downtime per year
- 99.999% (five nines) – 5.26 minutes of downtime per year
Related Resources
Case Studies

Whitepapers


On-demand Webinars


