Recently, we encountered a production incident where PostgreSQL 16.8 became unstable, preventing the application from establishing database connections. The same behavior was independently reproduced in a separate test environment, ruling out infrastructure and configuration issues. Further investigation identified the pg_prewarm extension as the source of the problem.
This blog post breaks down the failure, the underlying constraint, why it manifests only under specific configurations, and the corresponding short-term mitigation and long-term fix.
What pg_prewarm Does
Every time PostgreSQL restarts, its shared buffer cache (the region of RAM it uses to hold frequently accessed data pages from disk) starts completely cold. Every query that touches data must go to disk first. On large production systems, this cold-start penalty can be severe, sometimes taking hours before the cache naturally warms through organic traffic.
pg_prewarm solves this in two ways. First, it gives you manual control so you can explicitly warm specific tables or indexes on demand, useful before a heavy batch job or a known query workload. Second, it ships with an autoprewarm mode that, when enabled, continuously tracks which pages are resident in shared buffers and automatically replays that list after a restart with no manual intervention required. For high-traffic systems with large shared_buffers, this is operationally critical.
The BUG
In order for autoprewarm to dump the list of cached pages, PostgreSQL must build an array in memory containing one entry per page currently in shared buffers. Each entry (a BlockInfoRecord) is 20 bytes.
palloc(NBuffers * sizeof(BlockInfoRecord))NBuffers is the number of shared buffer slots derived directly from shared_buffers setting. PostgreSQL’s standard memory allocator, palloc, enforces a hard ceiling of 1 GB on any single allocation. Any palloc() call requesting more than 1 GB hits this limit and raises
ERROR: invalid memory alloc request size Working through the arithmetic:
Parameter | Value |
palloc hard limit | 1,073,741,824 bytes (1 GB) |
BlockInfoRecord size | 20 bytes per entry |
Max entries before wall (1 GB / 20 B) | ~53,687,091 = 53 M entries |
Buffer page size | 8 KB |
Max shared_buffers covered (53.7M x 8 KB) | ~429 GB |
The palloc() call fails once NBuffers × 20 bytes exceeds the 1 GB allocation limit. This threshold is reached at approximately 429 GB of shared_buffers. In other words, if shared_buffers is ≤ 429 GB, autoprewarm can successfully allocate an array of up to 1 GB, where each entry stores a page/block reference to be reloaded after restart. However, once shared_buffers exceeds this threshold, the required allocation surpasses the 1 GB limit, resulting in an error.
On modern systems with terabytes of RAM, this is no longer a theoretical edge case. Any configuration beyond ~429 GB of shared_buffers will trigger this limitation, as the single memory allocation crosses the maximum allowed size.

We observed this issue in production on PostgreSQL 16.8 with a configuration of 700 GB shared_buffers on a 1.5 TB server. The math is exact:
Buffers = shared_buffers / 8 KB = 700 GB / 8 KB = 91,750,400 buffer slots
palloc size = 91,750,400 x 20 bytes = 1,835,008,000 bytes (~1.75 GB)
Since:
1.75 GB > MaxAllocSize (1 GB)
PostgreSQL fails with:
ERROR: invalid memory alloc request size 1835008000
LOG: background worker "autoprewarm leader" exited with exit code 1
The Crash Loop
The crashloop is what makes this particularly damaging. When a background worker in PostgreSQL exits with a non-zero exit code, the postmaster is designed to restart the worker. So ,the following sequence repeats hundreds of times per minute:
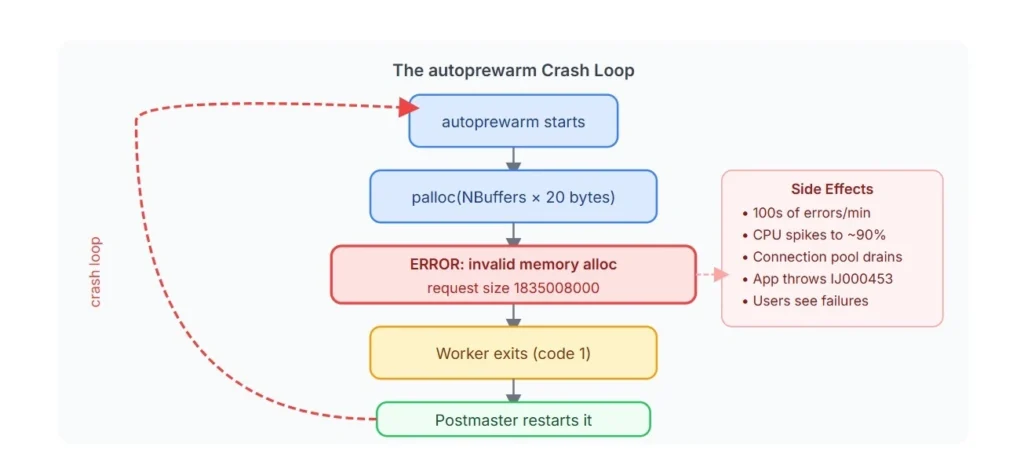
The database itself is fine. Data is intact, but a single background worker that has nothing to do with serving queries is thrashing hard enough to starve the entire application.
The Fix
The error was reported by multiple users in PostgreSQL 16.8, and a fix was committed to the PostgreSQL codebase, shipped in PostgreSQL 16.10. The fix was to replace the standard palloc call with palloc_extended, which bypasses the 1 GB hard limit and allows the allocation to succeed for any practically achievable shared_buffers value.
The discussion on the PostgreSQL hackers mailing list explored several alternative approaches, each worth understanding on its merits.
Streaming writes
Instead of pre-allocating the entire array, write entries to the dump file one at a time. The obstacle is structural: the file format places the total entry count at the beginning of the file, and you cannot know the final count until you have finished writing. Seeking back to patch the header is awkward, and buffer contents can change concurrently during the write.
Using blkreftable
Robert Haas proposed reusing common/blkreftable.h, a data structure originally built for incremental backup. For dense buffer sets, it converges toward 1 bit per block instead of 20 bytes, a substantial improvement. This is the right long-term direction, but too architecturally significant to backport safely to already-released minor versions.
Capping at 1 GB
Allocate as much as palloc allows and prewarm whatever fits. Correctly set aside: prewarming matters most precisely on the large-memory systems that would hit this limit, so capping it defeats the purpose.
palloc_extended was chosen because it is minimal, correct, and safe to backport across all affected minor versions, which is exactly what a fix in a minor release needs to be.
Immediate Mitigation
If you are running an affected version and cannot upgrade immediately, the autoprewarm worker can be disabled.
Step 1 – stop the crash loop
ALTER SYSTEM SET pg_prewarm.autoprewarm = off;
SELECT pg_reload_conf();
SHOW pg_prewarm.autoprewarm; -- verify: should return 'off'
Step 2 – To fully remove the extension:
DROP EXTENSION pg_prewarm;
-- Verify removal
SELECT * FROM pg_extension WHERE extname = 'pg_prewarm';
Step 3 – Remove pg_prewarm
To prevent it from loading on the next restart, remove pg_prewarm from shared_preload_libraries in postgresql.conf. Changes to shared_preload_libraries require a full PostgreSQL restart to take effect. After this verify no prewarm processes remain active:
SELECT pid, usename, application_name, backend_type
FROM pg_stat_activity
WHERE application_name ILIKE '%prewarm%';
After applying this, the crash loop will stop, and the CPU will normalize. This loses cache warming on restarts, which is an acceptable operational trade-off against total unavailability.
Permanent Resolution: Version Upgrade
The only permanent fix is to upgrade to PostgreSQL 16.10 or later. Since this is a minor version upgrade, no migration is required. It can be performed as an in-place binary upgrade.
For containerized deployments, simply update the PostgreSQL image tag in your Helm chart and perform a rolling update of the pods. Be sure to validate the change in a lower environment first, and then schedule the production rollout during a maintenance window. After the upgrade, pg_prewarm can be safely re-enabled if needed.
Summary
PostgreSQL minor version lag is an avoidable operational risk. As seen in this incident, running an outdated version (16.8) meant encountering a bug that had already been identified and fixed upstream in 16.10. Minor releases are strictly backward-compatible and contain only bug fixes, so there is little reason to defer them. Environments should be kept on or close to the latest minor version within their major release to avoid carrying known defects into production.
References
- PostgreSQL 16.10 Official Release Notes: https://www.postgresql.org/docs/release/16.10/
- PostgreSQL Hackers Mailing List, patch discussion: https://www.mail-archive.com/pgsql-hackers@lists.postgresql.org/msg198683.html
- PostgreSQL Hackers Mailing List, Robert Haas patch approval: https://www.mail-archive.com/pgsql-hackers@lists.postgresql.org/msg198939.html
- PostgreSQL pg_prewarm source, autoprewarm.c: https://github.com/postgres/postgres/blob/master/contrib/pg_prewarm/autoprewarm.c
- PostgreSQL versioning policy: https://www.postgresql.org/support/versioning/