System outages, hardware failures, or accidental data loss can strike without warning. What determines whether operations resume smoothly or grind to a halt is the strength of the disaster recovery setup. PostgreSQL is built with powerful features that make reliable recovery possible.
This post takes a closer look at how these components work together behind the scenes to protect data integrity, enable consistent restores, and ensure your database can recover from any failure scenario.
What is Disaster Recovery?
Disaster Recovery (DR) refers to a set of practices and strategies designed to back up and restore databases in the event of a disaster. In this context, a disaster means any event that renders the entire database environment unusable, such as:
- Cloud region outages – e.g., when AWS us-east-1 goes down and takes half the internet with it
- Physical disasters – fire, flood, earthquakes, or even a backhoe cutting fiber lines
- Catastrophic human error – like a faulty migration that corrupts critical tables
- Major security incidents – where you must rebuild from known good backups
- Power outages – extended downtime impacting availability
- Hardware failures – disks, memory, or server crashes
- Software failures – bugs, crashes, or corrupted processes
- Cyberattacks – ransomware, data breaches, or malicious tampering
- …and whatever else you can’t imagine!
The goal of DR is to ensure that the system can be quickly restored to a normal operational state in the event of an unexpected incident.
The Pillars of Business Continuity: RTO and RPO
Before designing a disaster recovery strategy, we must understand the two metrics that define it:
- RPO
- RTO
Recovery Point Objective (RPO) means the maximum amount of data you can afford to lose in case of a failure, measured in time. It answers the question, “When we recover, how far back in time will we be?” If you can only tolerate 5 minutes of data loss, your RPO is 5 minutes. RPO is primarily a Disaster Recovery metric, directly tied to your backup and WAL archiving strategy.
Recovery Time Objective (RTO) means the maximum acceptable time to restore service after a failure. It answers, “How long can the application be down?” If you need to be back online in 30 minutes, your RTO is 30 minutes. RTO is primarily a High Availability metric, often addressed through replication and failover mechanisms.
These two metrics are often in tension, and the goal is to bring both RTO and RPO as close to zero as possible. A low RPO requires frequent backups and robust WAL archiving, which can be costly. A low RTO requires on-demand compute resources and automation, which also adds cost. The art of DR planning is finding the balance between these opposing forces through risk management and cost-efficiency analysis.
The PostgreSQL Evolution
One of the most impressive aspects of Postgres is its flexibility and resilience right out of the box. Back in 2001, Postgres took a major leap forward by introducing crash recovery through Write-Ahead Logging (WAL), a milestone for data durability.
In 2005, the introduction of continuous backup and point-in-time recovery fortified Postgres through online physical backups and WAL archiving, enabling effective disaster recovery.
Over the following decade, Postgres evolved its continuous backup framework into the sophisticated replication system we know today, purpose-built to meet the high availability demands of modern organizations.
Before looking into Postgres backup and recovery infrastructure, let’s grasp some fundamental concepts.
What is a Backup?
A backup is a consistent copy of the data that can be used to recover the database. Without backups, there’s no real disaster recovery plan. There are two main types:
- Logical Backups
- Physical Backups
Logical Backups
Logical backups capture the contents of the database by exporting them into SQL scripts or other portable formats. It’s a set of commands that can recreate the database’s structure, including tables, schemas, constraints, and reinsert all the data. Common tools are:
- pg_dump – Creates a backup of a single database.
- pg_dumpall – Captures an entire cluster, including all databases, roles, and global objects.
Physical Backups
Physical backups are low-level copies of the database’s actual files at the storage layer. They capture the exact state of the database by copying its underlying data files directly. Common tools are:
- Pg_basebackup – The standard tool for online physical backups.
- pgBackRest or Barman – These are external tools that add automation and better management for large-scale environments.
Pros and Cons of Logical vs. Physical Backup:
Here’s a quick comparison of how logical and physical backups differ in capabilities and use cases:
Feature | Logical Backups | Physical Backups |
Data Copy | Yes | Yes |
Backup Single Tables | Yes | No |
Migrate Between Versions | Yes | No |
Recover to a Point in Time | No | Yes |
Incremental/Delta Restore | No | Yes |
In short, logical backups are flexible, portable, and ideal for migrations, while physical backups are faster, enable point-in-time recovery, and scale more effectively for large production environments.
Write-Ahead Logging (WAL)
To understand PostgreSQL recovery, we must understand WAL. It is the single most important component for durability.
In the infrastructure diagram below, there are four main components:
- Shared Buffers
- PGDATA
- pg_wal
- Postgres Backend
Let’s understand these first. Postgres stores data in 8-kilobyte pages within a directory called PGDATA. Transaction logs are stored in Write-Ahead Log (WAL) files, located in the pg_wal directory. Shared Buffers act as an in-memory cache to improve performance, and each client connection is handled by a dedicated process known as a Postgres Backend.
The golden rule of PostgreSQL is that any modification to a data page must be logged in the Write-Ahead Log (WAL) before the updated (“dirty”) page is written back to the data files.
When a backend requests a page from disk, that page is first loaded into the Shared Buffers before being returned to the backend. If the backend modifies the page, the change is first recorded in the Write-Ahead Log (WAL), not directly in the data files. This information is written to a WAL segment, which is why the mechanism is called Write-Ahead Logging, or simply WAL.

Write-Ahead Logging (WAL) is the binary representation of every exact change made to the data files. Each WAL record contains key details such as:
- Transaction ID – Identifies which transaction made the change
- Page Information – Specifies which database page was modified
- Redo Information – Describes how to reapply the change
- Undo Information – Describes how to reverse the change (used for rollbacks)
- CRC Checksum – Detects corruption and ensures data integrity
Each WAL record is first written to a small, high-speed memory area called the WAL Buffer. When a transaction is committed, PostgreSQL guarantees that the relevant WAL records are physically written to a file in the pg_wal directory. This marks the point of durability, once the WAL is safely on disk, the transaction is considered permanent. Even a sudden power loss cannot erase it.
After the WAL is written, PostgreSQL can delay writing the actual modified (“dirty”) data pages back to disk until a more optimal time.PostgreSQL coordinates this process through checkpointing. A checkpoint is a point in time when all dirty data pages are flushed to disk, ensuring that the data files are consistent with the WAL up to that point.
Once all changes recorded in a WAL file have been applied to the data files, that WAL segment is no longer needed for crash recovery. Instead of deleting it, PostgreSQL recycles the space for future WAL records. For Disaster Recovery, we leverage this mechanism by configuring WAL Archiving. Instead of letting PostgreSQL recycle old WAL files, we archive every single one to a separate, safe location.
So, in brief, to ensure reliable disaster recovery, it’s crucial to safeguard both Postgres database backups and the WAL archive. Together, these form the foundation for point-in-time recovery (PITR) and act as the bedrock of Postgres replication.
Continuous Backup and WAL Archiving
We need continuous backups and WAL archiving to ensure reliable disaster recovery.
Let’s now take a closer look at how these mechanisms work in practice.
When a Postgres server is running, it constantly generates WAL files that record every change made to the database. These WAL files are regularly archived to a separate storage location, often an object store like Amazon S3 or Google Cloud Storage.
Meanwhile, the data files inside the PGDATA directory need to be physically copied as part of what’s known as a base backup. Postgres provides an API to take these backups while the database remains online, these are referred to as hot physical backups.
The process is straightforward:
- Invoke the Postgres API to start the backup (pg_backup_start).
- Begin copying all files inside PGDATA. Depending on your database size, this step may take minutes or even hours.
- During this time, ongoing changes are still being logged in the WAL, ensuring nothing is lost. These WAL records are also continuously sent to the WAL archive.
One important thing to consider is that during an online backup, the data files inside PGDATA can change while they’re being copied because the database remains active. At first glance, this might look like corruption, since the files being backed up aren’t perfectly in sync with the current state of the database. However, this isn’t actually a problem.
Postgres is built to handle this scenario gracefully through the Write-Ahead Log (WAL). Every change made to the database is first recorded in the WAL, which is continuously archived. So even if the base backup includes some files that were mid-update, all subsequent or missing changes are safely captured in the WAL archive.
When restoring, Postgres first recovers the base backup and then replays the WAL files sequentially. This replay process reapplies every logged change that occurred after the backup began, bringing the database back to a fully consistent state, as if no interruption ever occurred.
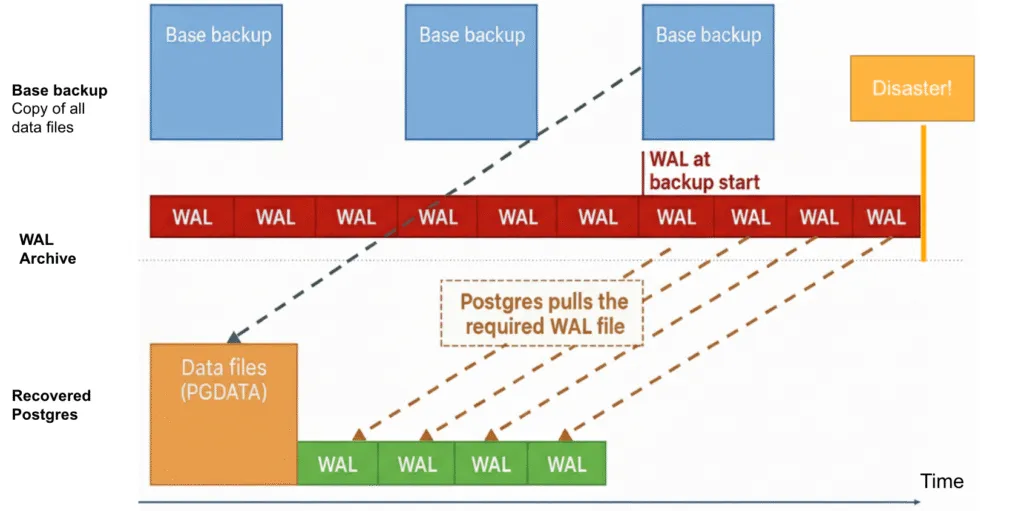
Finally, the backup process concludes by signaling the end of the copy operation through the Postgres API (pg_backup_stop) and waiting for the final WAL file to be archived. This ensures all transactions up to that point are captured, completing a consistent, restorable backup. For a backup to be restorable, we must have all WAL files from the start of the backup through to its completion.
So, if a production database is running smoothly, it continuously generates WAL files as transactions occur. Over time, these files are recycled and archived in sequence. Our responsibility is simply to schedule regular base backups and maintain continuous WAL archiving. Together, these ensure that the database can be restored to any specific point in time with complete accuracy.
Point-in-Time Recovery (PITR)
Point-in-Time Recovery (PITR) is one of the most powerful features, allowing us to restore your database to an exact moment in the past.
As long as we have a catalog of base backups and a continuous sequence of WAL files safely stored in the archive, PostgreSQL can reconstruct the database state at any specific point in time, from the end of your earliest base backup to the most recent committed transaction captured in the latest WAL segment.
So, imagine a developer accidentally runs DROP TABLE customers; at 2024-10-04 2:05 PM. With PITR, we can “rewind time” to just before that command was executed.
- Restore:
Start by provisioning a new PostgreSQL instance and restoring the latest base backup to it. - Configure Recovery:
Next, create a recovery. signal file and update the postgresql.conf to point to the actual WAL archive. Then define a recovery target, for example:recovery_target_time = ‘2024-10-04 14:04:00’
Just one minute before the accidental deletion. - Recover:
When you start PostgreSQL, it enters recovery mode and begins fetching WAL files from the archive. It sequentially replays every committed transaction recorded in the logs until it reaches the specified recovery target. - Promote:
Once recovery reaches the defined target time, PostgreSQL pauses. We then promote the server, turning it into a fully operational primary database which is restored to the exact state it was in before the incident, with the customers table safely intact.
By combining base backups and continuous WAL archiving, PostgreSQL gives us the power to recover data to any precise moment. All we require is to set up three things:
- Regular base backups
- Configuration of continuous WAL archiving
- Distribution of backups and WAL files across multiple locations for enhanced global RPO and RTO goals
High Availability vs. Disaster Recovery
High Availability (HA) and Disaster Recovery (DR) often go hand in hand, but they serve different purposes.
HA means having multiple live copies (nodes) of the production database running in sync. If one node goes down, slows, or becomes overloaded, another immediately takes over, keeping the system available with minimal disruption.
DR, on the other hand, comes into play when the entire environment fails, such as a regional outage or major data loss. It relies on backups and archived WAL files to fully restore the database to a specific point in time, often in a different region or data center.
Imagine a primary PostgreSQL cluster running in AWS us-east-1. If a single node fails, HA ensures continued service by promoting a standby within seconds. But if the entire region goes offline, DR takes over: the database is restored from backups and WAL archives in us-west-2, bringing it back to its exact pre-outage state. Once the primary region is back online, it can be resynchronized.
Together, HA and DR form a two-layer defense:
- HA keeps systems running during local failures,
- DR ensures recovery after large-scale disasters.
Conclusion:
PostgreSQL provides a solid foundation for enterprise-grade disaster recovery. With Write-Ahead Logging, physical base backups, and Point-in Time Recovery, it can meet strict RPO and RTO goals.
But true resilience comes from more than just backups – it requires an automated, well-architected, and regularly tested DR plan through periodic drills. Combined with a strong High Availability setup, this ensures both data safety and uninterrupted service, even in the face of failure.

Frequently Asked Questions (FAQs)
Q. What are the key metrics for defining a PostgreSQL disaster recovery strategy?
A robust strategy is defined by Recovery Point Objective (RPO), which sets the maximum acceptable data loss in time, and Recovery Time Objective (RTO), the limit for acceptable downtime. Balancing these metrics involves weighing the costs of frequent backups and storage against the need for rapid automated restoration mechanisms.
Q. How do logical and physical backups differ in the context of disaster recovery?
Physical backups are usually preferred for low-RPO, large-scale DR, while logical backups remain valuable for portability and selective recovery. They copy the actual data files, enabling point-in-time recovery and faster restoration for large datasets. Logical backups like pg_dump are portable and useful for version migrations but lack the ability to replay transaction logs for precise granular recovery.
Q. What role does Write-Ahead Logging (WAL) play in data durability?
WAL ensures data integrity by recording every modification to a transaction log before the change is written to the actual data file, a critical flow illustrated here: . If a crash occurs, PostgreSQL replays these logs from the archive to reconstruct the database state, guaranteeing that no committed transaction is lost.
Q. How does Point-in-Time Recovery (PITR) allow for precise data restoration?
PITR enables administrators to restore the database to a specific second, such as the moment before an accidental table deletion. This is achieved by first restoring a physical base backup and then sequentially replaying the archived WAL files up to the exact target timestamp defined in the recovery configuration.
Q. What is the distinction between High Availability (HA) and Disaster Recovery (DR)?
High Availability maintains system uptime during local component failures by using synchronized standby nodes for immediate automatic failover. Disaster Recovery is a broader safety net designed to rebuild the entire database environment from off-site backups and archives following catastrophic events like regional outages or massive data corruption.